#White Papers
Edge Computing, Fog Computing or both?
Cloud Computing
What is cloud computing?
A simplified definition of cloud computing is computing power provided as an online service. Depending on requirements, hardware (Infrastructure as a Service, IaaS), a platform (Platform as a Service, PaaS) or directly pre-configured software (Software as a Service, SaaS) can be rented from a cloud service provider. These solutions are particularly advantageous in the case of fluctuating storage requirements or if the acquisition of own hardware / software is to be avoided. A good example are providers of online storage and file management services. For example, Google Drive is such a service. Here, files are not stored on physical devices, but rather "in the cloud". In industrial applications, this data, which comes in many forms, could originate from IoT sensors. They can be sent to a cloud service such as Microsoft Azure. To do this, the data must be transferred from the physical devices in the field to the cloud. This is where edge computing and Fog computing come into play.
Insight and example of edge computing
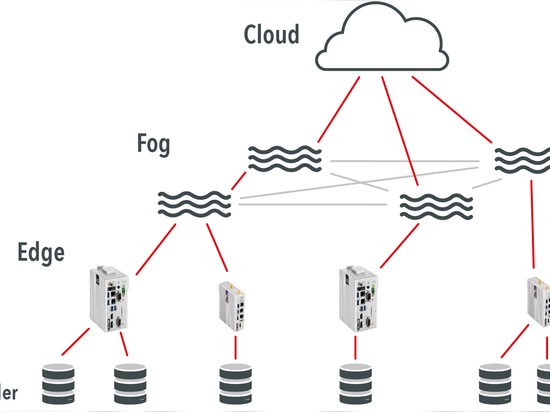
Edge computing, in contrast to fog computing, takes place directly at the end device, i.e. at the very edge of the network. With Edge Computing, the data from the connected sensors is collected, filtered, compressed, encrypted if necessary and sent on. So-called IoT edge gateways can be used for pre-processing at the end device. When using edge gateways, in contrast to integrated solutions, the service life of the connected sensors or the battery life can be extended, as complex analyses are outsourced. One example of a sensible use of edge computing is smart meters. Smart meters are intelligent electricity meters that produce a large amount of data by taking measurements at short intervals. With the help of Edge Computing, in this case through the embedded solution, data can be reduced before it is transported further over the network. You can find more information about Edge Computing in our short explanatory film.
Insight and example of Fog Computing
Fog computing is a computing layer between the cloud and the edge. With edge computing, large data streams can be sent directly to the cloud. Fog computing, on the other hand, can receive data from the edge layer before it reaches the cloud. Then, only relevant data is stored in the cloud. At the same time, the irrelevant data can be deleted or analysed in the Fog layer for remote access or to inform localised learning models. A good example of Fog computing would be an embedded application on a production line where a temperature sensor connected to an edge gateway measures the temperature every single second. This data would then be sent to the cloud to monitor temperature spikes. Imagine that all temperature measurements, every single second of a 24/7 measurement cycle, are sent to the cloud. With a Fog layer, the edge gateway would first send the data to the Fog layer via a localised network. Based on certain parameters, it is decided here whether and which data is sent to the cloud. This reduces the data traffic. For simple temperature readings, this data saving may seem negligible. But imagine the impact if these constant data streams were filled with much more complex information or large files, such as images or videos.
Advantages of Fog Computing
One advantage is the efficiency of data traffic and the reduction of latency. Implementing a Fog layer reduces the data that the cloud receives for its specific embedded application. This allows it to respond directly to the data from the Fog layer. Other advantages include less storage space needed for the cloud application and faster data transfer due to the reduced data volume.
Disadvantages of Fog Computing
It is clear that Fog computing cannot replace edge computing. However, edge computing can function without fog computing. Fog Computing is a complex system that has to be integrated into an existing infrastructure. This involves a lot of effort. Thus, Fog Computing is not suitable for every scenario. However, for some applications, the above advantages can be attractive if a direct edge-to-cloud data architecture is used.
Differences between Edge Computing and Fog Computing - Functionalities
The terms Fog and Edge Computing are often used redundantly. However, there is now a well-defined demarcation between the two solutions. Accordingly, Fog Computing is a generic term for data pre-processing in the local network, Edge Computing is a special form of data pre-processing. A Fog device knows all devices present in the domain. During analyses, the other devices can be accessed and communicated with. Fog devices can make decisions based on the data they receive and cache small amounts of data. The Edge, on the other hand, performs tasks such as filtering and summarising data. Edge devices do not know each other and therefore do not interact.
Fog nodes are usually devices that already exist in the network. They are located in an additional hierarchical level between the end devices and the cloud. Edge computing, on the other hand, takes place directly on or even in the end device.
Choosing the right hardware and software
The idea of Fog Computing is based on using devices that are already present in the network (e.g. industrial routers, gateways, servers). This means that special hardware is not required here. However, the already existing devices must be integrated into a Fog network with appropriate software. Such software is now available from many providers. Mostly, it is the cloud providers themselves who provide software solutions for networking from the Fog level to the respective cloud.
Edge computing, on the other hand, is mostly based on hardware. The edge computing functions mentioned above are executed on many end devices. These are embedded in existing systems and are provided by the manufacturer. If the data of an end device without such functionality is to be processed at the edge, additional hardware such as an edge gateway is required. The devices have a wide variety of interfaces to connect different end devices.
In terms of the necessary hardware or type of industrial computer, an edge gateway can easily be used for the same purpose as a Fog server. The reason for this is that there are differences in data collection and processing, but not in the functions and capabilities of the hardware.